所用数据可从这里下载(提取码1fl1),数据说明可参考此文件,目标是分析建筑物的节能之星评分(ENERGY STAR Score)与哪些因素有关,并对之进行预测。
一个完整的机器学习项目主要有以下几个步骤组成:
- 探索性数据分析(EDA)
- 特征工程和选择(Feature Engineering and Selection)
- 机器学习模型比较(Model Comparison)
- 超参数调优(Hyperparameters Tuning)
- 模型评估和解释(Model Evaluation and Interpretation)
1. 探索性数据分析
- Read data and Confirm data type
import pandas as pd import numpy as np import seaborn as sns import matplotlib.pyplot as plt from IPython.core.pylabtools import figsize from sklearn.model_selection import train_test_split from sklearn.feature_extraction import DictVectorizer from sklearn.preprocessing import Imputer, FunctionTransformer from sklearn_pandas import DataFrameMapper, CategoricalImputer from sklearn.pipeline import FeatureUnion, Pipeline data = pd.read_csv('Energy_and_Water_Data_Disclosure_for_Local_Law_84_2017__Data_for_Calendar_Year_2016.csv') data = data.replace({'Not Available': np.nan}) numeric_units = ['ft²','kBtu','Metric Tons CO2e','kWh','therms','gal','Score'] for col in list(data.columns): for unit in numeric_units: # Select columns that should be numeric if unit in col: # Convert the data type to float data[col] = data[col].astype(float) - Check missing value
def missing_values_table(df): # Total missing values mis_val = df.isnull().sum() # Percentage of missing values mis_val_percent = 100 * df.isnull().sum() / len(df) # Make a table with the results mis_val_table = pd.concat([mis_val, mis_val_percent], axis=1) # Rename the columns mis_val_table = mis_val_table.rename(columns = {0 : 'Missing Values', 1 : '% of Total Values'}) # Sort the table by percentage of missing descending mis_val_table = mis_val_table[mis_val_table.iloc[:,1] != 0].sort_values('% of Total Values', ascending=False).round(1) # Return the dataframe with missing information return mis_val_table missing_df = missing_values_table(data) ### drop the columns that have >50% missing values missing_columns = list(missing_df[missing_df['% of Total Values'] > 50].index) print('We will remove %d columns.' % len(missing_columns)) data = data.drop(columns = missing_columns) - Remove Outliers
# Calculate first and third quartile first_quartile = data['Site EUI (kBtu/ft²)'].describe()['25%'] third_quartile = data['Site EUI (kBtu/ft²)'].describe()['75%'] iqr = third_quartile - first_quartile #Interquartile range data = data[(data['Site EUI (kBtu/ft²)'] > (first_quartile - 3 * iqr)) & \ (data['Site EUI (kBtu/ft²)'] < (third_quartile + 3 * iqr))] - Histogram of the target
### Histogram of the Energy Star Score(the target) data = data.rename(columns = {'ENERGY STAR Score': 'score'}) plt.style.use('fivethirtyeight') plt.hist(data['score'].dropna(), bins = 100, edgecolor = 'k') plt.xlabel('Score'); plt.ylabel('Number of Buildings') plt.title('Energy Star Score Distribution')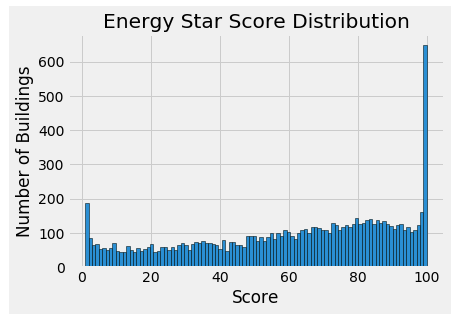
- Correlations between the target and numerical variables
# Find all correlations and sort correlations_data = data.corr()['score'].sort_values() # Print the most negative correlations print(correlations_data.head(15), '\n') # Print the most positive correlations print(correlations_data.tail(15)) - Plot distributions of the target for a categorical variable
# Create a list of building types with more than 100 observations types = data.dropna(subset=['score']) types = types['Largest Property Use Type'].value_counts() types = list(types[types.values > 100].index) # Plot each building sns.set(font_scale = 1) figsize(6, 5) for b_type in types: # Select the building type subset = data[data['Largest Property Use Type'] == b_type] # Density plot of Energy Star scores sns.kdeplot(subset['score'].dropna(), label = b_type, shade = False, alpha = 0.8) # label the plot plt.xlabel('Energy Star Score', size = 10) plt.ylabel('Density', size = 10) plt.title('Density Plot of Energy Star Scores by Building Type', size = 14)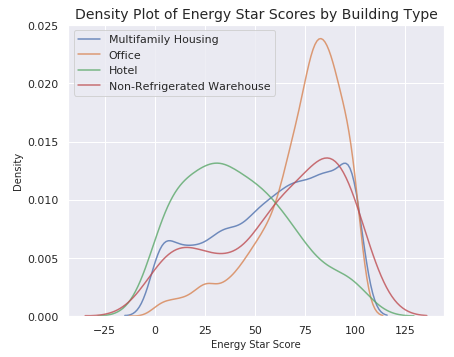
- Visualization of the target vs a numerical variable and a categorical variable
temp = data.dropna(subset=['score']) # Limit to building types with more than 100 observations temp = temp[temp['Largest Property Use Type'].isin(types)] # Visualization figsize(9, 7.5) sns.set(font_scale = 2) sns.lmplot('Site EUI (kBtu/ft²)', 'score', hue = 'Largest Property Use Type', data = temp, \ scatter_kws = {'alpha': 0.8, 's': 60}, fit_reg = False, size = 12, aspect = 1.2) # Plot labeling plt.xlabel("Site EUI", size = 28) plt.ylabel('Energy Star Score', size = 28) plt.title('Energy Star Score vs Site EUI', size = 36)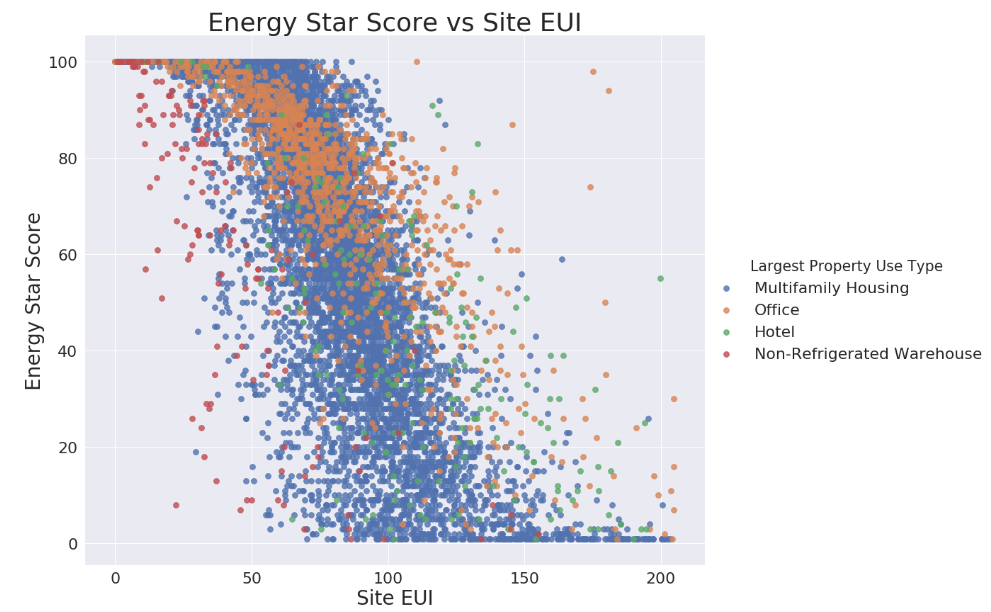
- Pair Plot
# Extract the columns to plot plot_data = data[['score', 'Site EUI (kBtu/ft²)', 'Weather Normalized Source EUI (kBtu/ft²)']] # Replace the inf with nan plot_data = plot_data.replace({np.inf: np.nan, -np.inf: np.nan}) # Rename columns plot_data = plot_data.rename(columns = {'Site EUI (kBtu/ft²)': 'Site EUI', \ 'Weather Normalized Source EUI (kBtu/ft²)': 'Weather Norm EUI'}) # Drop na values plot_data = plot_data.dropna() # Function to calculate correlation coefficient between two columns def corr_func(x, y, **kwargs): r = np.corrcoef(x, y)[0][1] ax = plt.gca() ax.annotate("r = {:.2f}".format(r), xy=(.2, .8), xycoords=ax.transAxes, size = 20) # Create the pairgrid object figsize(9,7.5) sns.set(font_scale = 1) grid = sns.PairGrid(data = plot_data, height = 3) # Upper is a scatter plot grid.map_upper(plt.scatter, color = 'red', alpha = 0.6) # Diagonal is a histogram grid.map_diag(plt.hist, color = 'red', edgecolor = 'black') # Bottom is correlation and density plot grid.map_lower(corr_func); grid.map_lower(sns.kdeplot, cmap = plt.cm.Reds) # Title for entire plot plt.suptitle('Pairs Plot of Energy Data', size = 24, y = 1.02)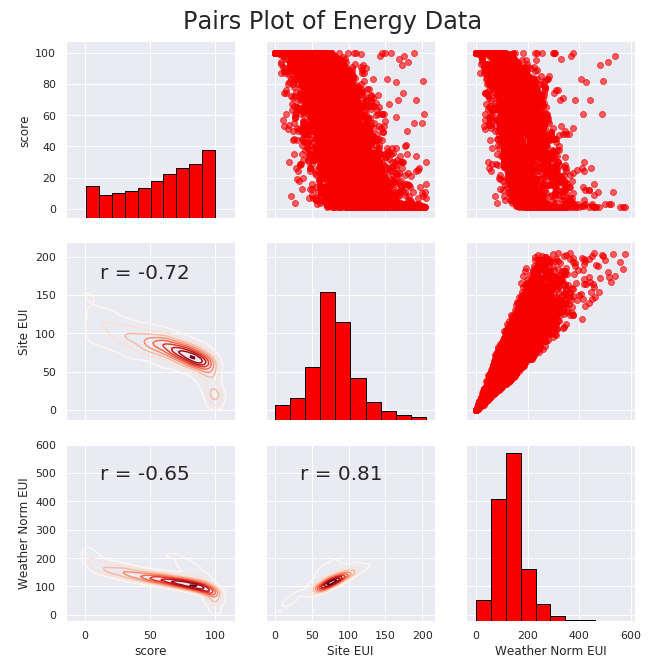
2. 特征工程和选择
- 特征工程
### Extract the buildings with no score and the buildings with a score numeric_cols = data.columns[data.dtypes!=object].tolist() categorical_cols = ['Borough', 'Largest Property Use Type'] no_score = data[numeric_cols+categorical_cols][data['score'].isna()] #for prediction score = data[numeric_cols+categorical_cols][data['score'].notnull()] ### Separate out the features and targets features = score.drop(columns='score') targets = pd.DataFrame(score['score']) numeric_cols.remove('score') ### Split into 70% training and 30% testing set X, X_test, y, y_test = train_test_split(features, targets, test_size = 0.3, random_state = 42) ### Apply numeric imputer numeric_imputer = [([feature], Imputer(strategy="median")) for feature in numeric_cols] numeric_imputation_mapper = DataFrameMapper(numeric_imputer, input_df=True, df_out=True) ### Create columns with log of numeric columns def add_log(df): temp = df.copy() for col in numeric_cols: temp['log_' + col] = np.sign(df[col])*np.log(np.abs(df[col])+1) return temp ### Numerical Transformations numeric = Pipeline([("num_mapper", numeric_imputation_mapper), ("add_log", FunctionTransformer(add_log, validate=False))]) ### Apply categorical imputer category_imputer = [(feature, CategoricalImputer(strategy='constant', fill_value='Missing')) \ for feature in categorical_cols] categorical_imputation_mapper = DataFrameMapper(category_imputer,input_df=True,df_out=True) ### One-hot Encode def dictify(df): return df.to_dict("records") onehot = Pipeline([("dictifier", FunctionTransformer(dictify, validate=False)), \ ("dictvectier", DictVectorizer(sparse=False))]) ### Categorical Transformations category = Pipeline([("cat_mapper", categorical_imputation_mapper), \ ("onehot", onehot)]) ### Combine the numeric and categorical transformations num_cat_union = FeatureUnion([("num_trans", numeric), ("cat_trans", category)])